Arabic Text Diacritization Using Deep Neural Networks and Transformer-Based Architectures
DOI:
https://doi.org/10.59543/kadsa.v1i.15077Keywords:
Arabic Diacritization; Natural Language Processing (NLP); Sequence-to-Sequence Models; Transformer ArchitectureAbstract
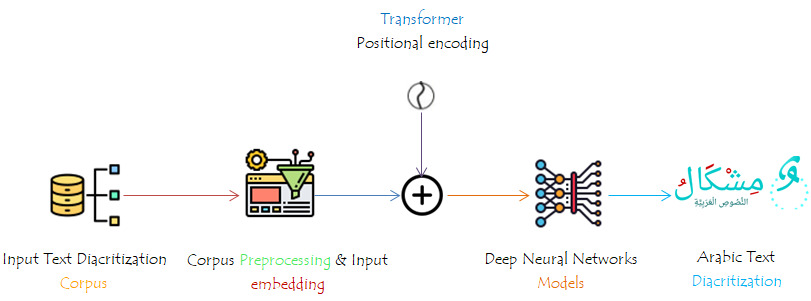
This study investigates the application of deep learning architectures for automatic Arabic text diacritization, with a particular focus on character-level neural networks. Four architectures were implemented: a Transformer encoder-decoder, a BiGRU model, a baseline stacked BiLSTM, and a CBHG model. Diacritic Error Rate (DER) and Word Error Rate (WER) were used as evaluation metrics, with training and evaluation conducted on the Tashkeela corpus. The results show that the CBHG model achieved faster inference times while slightly outperforming the Transformer encoder-decoder in diacritic accuracy. However, the findings also suggest that the Transformer model may yield better performance with larger datasets, improved parameter tuning, and increased model capacity.